在人工智能基础学习中,掌握数据处理、分类算法和可视化技术是至关重要的。本文将介绍如何使用Jupyter Notebook完成Iris数据集的Fisher线性分类任务,并深入探讨数据可视化技术的应用。Iris数据集是一个经典的多变量数据集,包含三种鸢尾花的特征数据,非常适合用于分类算法的入门实践。
我们需要导入必要的Python库,包括pandas用于数据处理,numpy用于数值计算,matplotlib和seaborn用于数据可视化,以及scikit-learn中的Fisher线性判别分析(LDA)模块。在Jupyter中,可以通过代码单元格依次安装和导入这些库。
加载Iris数据集。scikit-learn库内置了该数据集,我们可以直接使用load_iris()函数获取数据。数据集包括特征(如花萼长度、宽度,花瓣长度、宽度)和标签(鸢尾花种类)。通过pandas的DataFrame结构,可以方便地查看数据的基本信息,如描述性统计和缺失值情况。
数据预处理是机器学习的关键步骤。我们需要检查数据是否需要标准化或归一化,但Iris数据集通常已经经过处理,可以直接使用。然后,将数据集划分为训练集和测试集,以确保模型的泛化能力。scikit-learn的train<em>test</em>split函数可以轻松实现这一点。
Fisher线性分类(通过LDA实现)是一种监督学习算法,旨在找到最佳投影方向,使得类间距离最大化、类内距离最小化。在scikit-learn中,使用LinearDiscriminantAnalysis类可以快速构建模型。初始化LDA模型,然后使用训练数据拟合模型,最后对测试数据进行预测。通过准确率、混淆矩阵等指标评估模型性能,可以发现Fisher分类在Iris数据集上通常能达到很高的准确率。
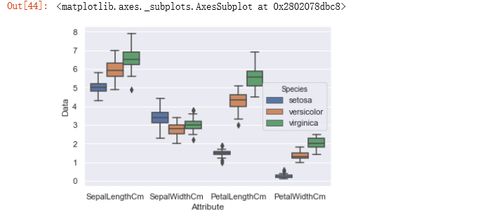
数据可视化技术在此过程中扮演着重要角色。我们可以使用matplotlib和seaborn绘制各种图表来理解数据和模型结果。例如:
- 散点图:展示特征之间的关系,如花萼长度与宽度的分布,并用颜色区分不同类别。
- 直方图和箱线图:分析单个特征的分布和异常值。
- 混淆矩阵热图:直观显示分类结果的正确与错误情况。
- 决策边界图:通过绘制LDA的投影方向,可视化分类边界。
在Jupyter中,这些图表可以内联显示,便于交互式分析和调试。通过可视化,我们不仅能验证模型的有效性,还能深入理解数据的内在结构。
本实践涵盖了人工智能基础软件开发的核心环节:从数据加载和预处理,到应用Fisher线性分类算法,再到数据可视化分析。通过Jupyter Notebook的交互环境,开发者可以高效地实验和学习。这种项目不仅巩固了机器学习基础,还为更复杂的AI应用打下了坚实基础。建议读者扩展此项目,例如尝试其他分类算法或添加更多可视化技巧,以进一步提升技能。